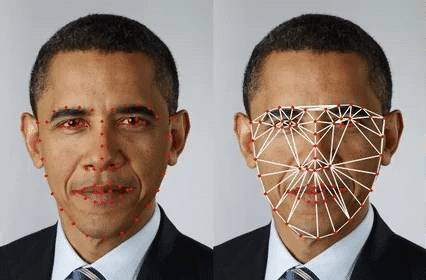
LFW es una base de datos pública para la evaluación de motores de biometría facial. Contiene 13233 imágenes de 5749 personas distintas, y 1680 personas tienen dos o más imágenes.
Utilizaremos esta base de datos para visualizar cómo funciona el motor de biometría facial de Veridas.
Reducción de dimensiones
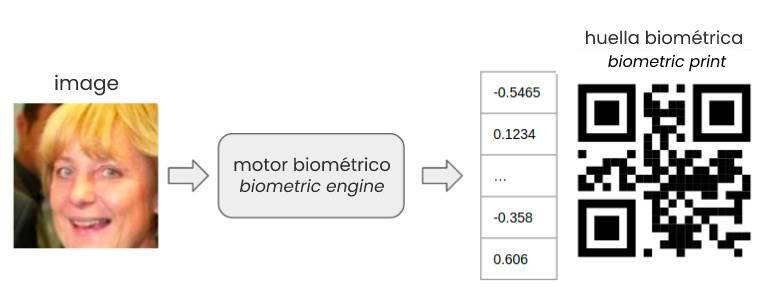
Como hemos comentado anteriormente, las huellas biométricas son vectores numéricos con muchas dimensiones. Para que las personas podamos visualizar las huellas biométricas necesitamos reducir el número de dimensiones a 3 (el espacio) o a 2 dimensiones (el plano).
Existen algoritmos que permiten reducir las dimensiones de un vector numérico. Uno de los más populares es TSNE, que se basa en reducir la dimensión de los vectores manteniendo la distancia que hay entre ellos. Por ejemplo, en nuestro caso, partimos de una huella biométrica con 512 dimensiones y el algoritmo de TSNE se encargará de reducirla a tan solo 3 tratando de mantener las distancias que hay entre las distintas huellas biométricas.
Tensorflow Projector es una herramienta de Google que nos va a permitir aplicar la reducción de dimensionalidad con TSNE y visualizar lo que ha aprendido el motor de biometría durante el entrenamiento.
La siguiente visualización muestra cómo el algoritmo TSNE encuentra una representación de las huellas biométricas en el espacio de 3 dimensiones. Es un proceso iterativo que empieza con una representación aleatoria y la va mejorando progresivamente.











![[DEMO GRATUITA]: Descubre cómo funciona nuestra tecnología en vivo](https://no-cache.hubspot.com/cta/default/19918211/c1172a0c-a16c-42db-a994-41f0758530a2.png)











