In this post, we will first explain how biometric facial recognition engines work and then conduct experiments to visualize how the Veridas engine functions.
What Is Facial Biometrics?
Facial biometrics, also known as facial recognition biometrics, is a technology that identifies or verifies a person by analyzing the unique features of their face. It converts these features into a mathematical representation called a biometric faceprint, which can be compared against stored data to authenticate identity.
How does Facial Biometrics Work?
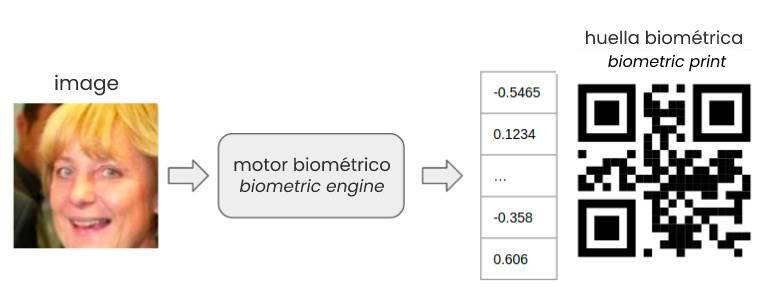
A facial recognition biometrics systems engine is an algorithm that transforms a photo of a person’s face into a biometric faceprint. This faceprint is a set of coordinates constructed from the unique characteristics of a person’s face.
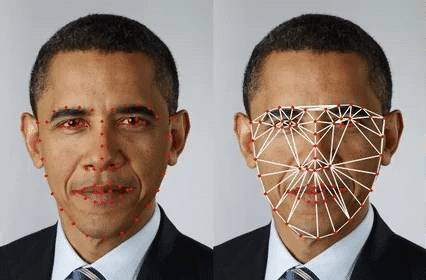
In the past, engineers manually designed faceprints based on the distance between characteristic points of the face (e.g., the distance between the nose and the mouth, between the eyes, etc.), as shown in the following image:
However, modern systems use artificial neural networks that learn from databases with millions of examples, resulting in far more accurate and reliable facial biometrics. Therefore, in this article, we will focus on biometrics obtained from neural networks, as they represent the current state of the art in biometric facial recognition.
What is a biometric faceprint?
A biometric faceprint is analogous to the coordinates used to describe the position of a city on a map. When we train a neural network with millions of images of people, it learns to transform the images into positions on a multidimensional map. Images of the same person are placed close together, while images of different people are further apart. Unlike traditional maps with two dimensions, these biometric maps can have an arbitrary number of dimensions, such as 512.
The following image visually represents this concept. In this example, images less than 100 km apart belong to the same person, while images more than 100 km apart belong to different people. The closer the images are to each other, the more confident we are that they belong to the same person.
It’s important to note that to compare the similarity between two images, it’s sufficient to have the biometric faceprints; storing the actual images is unnecessary. In this article, we use images as a visual resource, but the correct visualization involves only the biometric faceprints.
A biometric faceprint can be represented as a numeric vector or a biometric QR code.
Security and Privacy in Biometric Facial Recognition
Biometric faceprints are irreversible, meaning it’s impossible to reconstruct a person’s image from the biometric faceprint. Moreover, each facial recognition biometrics engine generates different and incompatible biometric faceprints. Comparing biometric faceprints from different engines is meaningless because each engine learns a unique and different map.
These facts mean that if a biometric faceprint is stolen, it’s not a problem. The thief would be unable to recover the person’s face from the biometric faceprint. A new biometric can be created with a different biometric engine, rendering the previous biometric useless, as each biometric model generates an entirely different map.
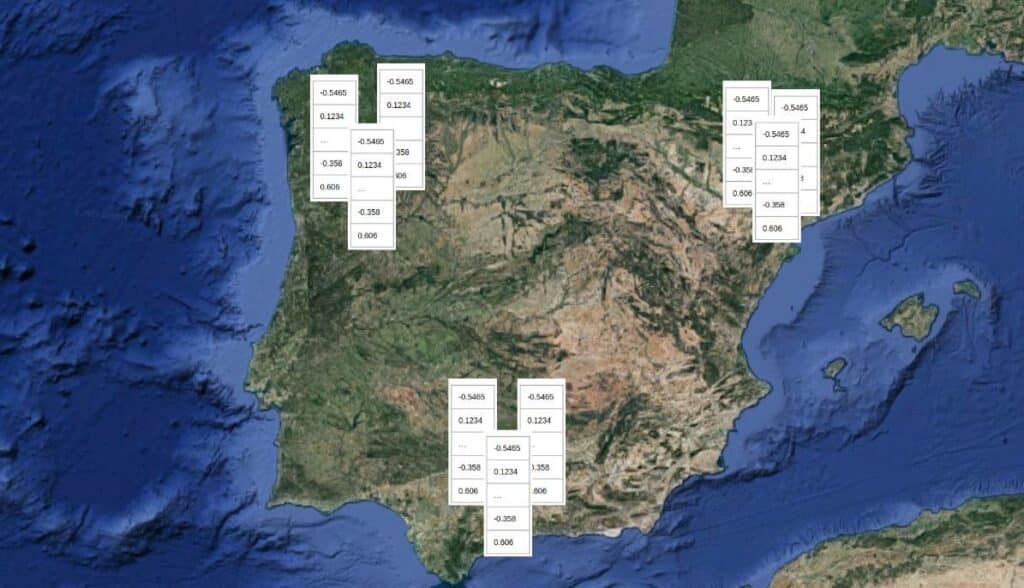
The image below illustrates the map that a different biometric engine would have learned. From the training “recipe” of one biometric engine, an infinite number of different biometric engines can be trained with the same level of accuracy. The first model placed the biometric faceprints on the Iberian Peninsula, while the second placed them around the Adriatic Sea.
How Do You Use Face Biometrics?
Facial biometrics are used in various applications, from unlocking smartphones to securing access to buildings and systems. Biometric facial recognition software processes the biometric faceprint and compares it against stored data to verify identity.
Biometric Facial Recognition Software
Modern facial recognition systems and biometrics employ advanced software that leverages artificial intelligence and machine learning. These systems can quickly and accurately identify individuals, enhancing security and user experience.
Visualizing biometric faceprints
Labeled Faces in the Wild (LFW)
LFW is a public database for the evaluation of facial biometric engines. It contains 13233 images of 5749 different people, and 1680 people have two or more images.
We will use this database to visualize how the Veridas facial biometrics engine works.
Dimension reduction
As mentioned above, biometric faceprints are numerical vectors with many dimensions. For people to be able to visualize biometric faceprints, we need to reduce the number of dimensions to 3 (space) or 2 dimensions (plane).
Some algorithms allow us to reduce the dimensions of a numeric vector. One of the most popular is TSNE, which is based on reducing the dimension of the vectors while maintaining the distance between them. For example, in our case, we start from a biometric faceprint with 512 dimensions and the TSNE algorithm will reduce it to only 3 while trying to maintain the distances between the different biometric faceprints.
Tensorflow Projector is a Google tool that will allow us to apply dimensionality reduction with TSNE and visualize what the biometrics engine has learned during training.
The following visualization shows how the TSNE algorithm finds a representation of the biometric faceprints in 3-dimensional space. It is an iterative process that starts with a random representation and improves it progressively.
Experiment 1: Identities with more than 5 photos
For the first experiment, we will keep the people with more than 5 photos in the LFW database and, for each of these people, we will randomly choose 5 photos.
The following visualization shows how each person occupies a unique place in the space. The 5 photos of each person are so close together that it almost looks like only one photo exists. This shows us that the biometric engine is highly accurate when verifying a person against themselves, preventing someone else from impersonating us.
If we zoom in a bit, we can see (with a bit of effort because the images are so close together) that each person has 5 photos.
Finally, we can scan specific images and study which images have the closest biometric faceprint. As can be seen in the following visualization, in all cases, the 4 closest images always correspond to the same person. But it is also very interesting to see how the next closest image is already of a different person, located at a much greater distance (the distance between the images is the number next to the person’s name on the right side of the image).
In short, the biometrics engine behaves ideally: it groups all the faces of the same person at the same point in a very compact way, and never two different people share the same location.
Experiment 2: Only one image per person
In this second experiment, each person will have only one image. This will make the distance between the biometric faceprints much more significant than in the previous experiment, where there were several images of each person. Therefore, the TSNE algorithm will have to generate a representation that looks for similarities between different people.
The visualization below shows how all images are grouped into a single sphere. This behavior is ideal because it implies that the model has no relevant gender or race biases. If it did, instead of a single sphere, we would be looking at several: e.g. one sphere for men and another for women.
Finally, if we look for the closest images we can see how they are people of different race or gender in many occasions, which corroborates the absence of significant biases of the biometric model. It is also relevant to see how the numerical distance between the images is much larger than in the first experiment, which is logical because they are different people.
Conclusions
In the experiments carried out, we have been able to observe that:
Facial biometrics is not a black box: There are techniques that allow us to visualize and understand how it works.
The Veridas biometric facial recognition model works perfectly, as demonstrated in the example with the LFW database: it groups all the faces of the same person in a tiny region, and there is a significant distance between different people.
The Veridas facial biometrics model shows no significant bias concerning race or gender.
By understanding how biometric facial recognition works and its applications, we can appreciate the advancements in security and technology that facial biometrics bring to various industries.
FAQs
What is biometric facial recognition?
Biometric facial recognition is a technology that identifies or verifies a person’s identity by analyzing the unique features of their face and converting them into a digital faceprint.
Is facial recognition software secure?
Yes, modern facial recognition software uses advanced encryption and privacy techniques to ensure the safety of biometric data, such as irreversible faceprints that prevent reverse engineering.
How are biometric faceprints created?
Biometric faceprints are generated by analyzing facial features and converting them into a multidimensional numerical vector representing a person’s unique facial structure.
Can someone steal my biometric data?
While biometric faceprints can technically be stolen, they are irreversible and specific to each system, making them nearly impossible to misuse outside their original context.
Does facial recognition software work for everyone?
Facial recognition software is highly accurate, though some systems may exhibit biases. However, advanced systems like Veridas’ have demonstrated minimal bias across race and gender.
How is Veridas improving facial biometrics?
Veridas continuously enhances its facial biometric systems, focusing on improving accuracy, eliminating bias, and ensuring user privacy.
In this article you will find...
Need help?
I am Edu Gozalo,
Digital Identity consultant at Veridas. If you need to talk to our team, book a meeting.
Simplify entry, save time, and manage your stadium parking more efficiently.
Quick Facial Parking Access
Enter the parking area in under 1 second with facial recognition technology.
Stress-Free Experience
Simplify the ticket purchase process and enable attendees to enjoy a hands-free experience throughout their stadium stay.
Enhanced Security
Elevate your parking security for peace of mind.
Facial Ticketing
Protect your Stadium with our end-to-end identity verification platform, featuring biometric and document verification, trusted data sources, and fraud detection.
Instant Identity Verification
Verify your attendees’ identity remotely in less than 1 minute.
Pop-up Convenience
Simplify the ticket purchase process and enable attendees to enjoy a hands-free experience throughout their stadium stay.
Maximum Security
Enhance the security of the purchase process, eliminating the possibility of fraud, resale, and unauthorized access.













![[FREE DEMO]: Find out how our technology works live](https://no-cache.hubspot.com/cta/default/19918211/9d2f027d-2e80-4f2b-8103-8f570f0ddc7c.png)















